Should I use large language models for keyword research? Can these models think? Is ChatGPT my friend?
If you’ve been asking yourself these questions, this guide is for you.
This article covers what SEOs need to know about large language models, natural language processing and everything in between.
Large language models, natural language processing and more in simple terms
There are two ways to get a person to do something – tell them to do it or hope they do it themselves.
When it comes to computer science, programming is telling the robot to do it, while machine learning is hoping they do it themself. The former is supervised machine learning, and the latter is unsupervised machine learning.
Natural language processing (NLP) is a way to break down the text into numbers and then analyze it using computers.
Computers analyze patterns in words and, as they get more advanced, in the relationships between the words.
An unsupervised natural language machine learning model can be trained on many different kinds of datasets.
For example, if you trained a language model on average reviews of the movie Waterworld, you would have a result that is good at writing (or understanding) reviews of the movie Waterworld.
If you trained it on the two positive reviews that I did of the movie Waterworld, it would only understand those positive reviews.
Large language models (LLMs) are neural networks with over a billion parameters. They are so big that they’re more generalized.
They are not only trained on positive and negative reviews for Waterworld but also on comments, Wikipedia articles, news sites, and more.
Machine learning projects work with context a lot – things within context and out of context.
If you have a machine learning project that works to identify bugs and show it a cat, it won’t be good at that project.
This is why stuff like self-driving cars is so difficult: there are so many out-of-context problems that it’s very difficult to generalize that knowledge.
LLMs seem and can be a lot more generalized than other machine learning projects. This is because of the sheer size of the data and the ability to crunch billions of different relationships.
Let’s talk about one of the breakthrough technologies that allow for this – transformers.
Explaining transformers from scratch
A type of neural networking architecture, transformers have revolutionized the NLP field.
Before transformers, most NLP models relied on a technique called recurrent neural networks (RNNs), which processed text sequentially, one word at a time. This approach had its limitations, such as being slow and struggling to handle long-range dependencies in text.
Transformers changed this.
In the 2017 landmark paper, “Attention is All You Need,” Vaswani et al. introduced the transformer architecture.
Instead of processing text sequentially, transformers use a mechanism called “self-attention” to process words in parallel, allowing them to capture long-range dependencies more efficiently.
Previous architecture included RNNs and long short-term memory algorithms.
Recurrent models like these were (and still are) commonly used for tasks involving data sequences, such as text or speech.
However, these models have a problem. They can only process the data one piece at a time, which slows them down and limits how much data they can work with. This sequential processing really limits the ability of these models.
Attention mechanisms were introduced as a different way of processing sequence data. They allow a model to look at all the pieces of data at once and decide which pieces are most important.
This can be really helpful in many tasks. However, most models that used attention also use recurrent processing.
Basically, they had this way of processing data all at once but still needed to look at it in order. Vaswani et al.’s paper floated, “What if we only used the attention mechanism?”
Attention is a way for the model to focus on certain parts of the input sequence when processing it. For instance, when we read a sentence, we naturally pay more attention to some words than others, depending on the context and what we want to understand.
If you look at a transformer, the model computes a score for each word in the input sequence based on how important it is for understanding the overall meaning of the sequence.
The model then uses these scores to weigh the importance of each word in the sequence, allowing it to focus more on the important words and less on the unimportant ones.
This attention mechanism helps the model capture long-range dependencies and relationships between words that might be far apart in the input sequence without having to process the entire sequence sequentially.
This makes the transformer so powerful for natural language processing tasks, as it can quickly and accurately understand the meaning of a sentence or a longer sequence of text.
Let’s take the example of a transformer model processing the sentence “The cat sat on the mat.”
Each word in the sentence is represented as a vector, a series of numbers, using an embedding matrix. Let’s say the embeddings for each word are:
The: [0.2, 0.1, 0.3, 0.5]
cat: [0.6, 0.3, 0.1, 0.2]
sat: [0.1, 0.8, 0.2, 0.3]
on: [0.3, 0.1, 0.6, 0.4]
the: [0.5, 0.2, 0.1, 0.4]
mat: [0.2, 0.4, 0.7, 0.5]
Then, the transformer computes a score for each word in the sentence based on its relationship with all the other words in the sentence.
This is done using the dot product of each word’s embedding with the embeddings of all the other words in the sentence.
For example, to compute the score for the word “cat,” we would take the dot product of its embedding with the embeddings of all the other words:
These scores indicate the relevance of each word to the word “cat.” The transformer then uses these scores to compute a weighted sum of the word embeddings, where the weights are the scores.
This creates a context vector for the word “cat” that considers the relationships between all the words in the sentence. This process is repeated for each word in the sentence.
Think of it as the transformer drawing a line between each word in the sentence based on the result of each calculation. Some lines are more tenuous, and others are less so.
The transformer is a new kind of model that only uses attention without any recurrent processing. This makes it much faster and able to handle more data.
How GPT uses transformers
You may remember that in Google’s BERT announcement, they bragged that it allowed search to understand the full context of an input. This is similar to how GPT can use transformers.
Let’s use an analogy.
Imagine you have a million monkeys, each sitting in front of a keyboard.
Each monkey is randomly hitting keys on their keyboard, generating strings of letters and symbols.
Some strings are complete nonsense, while others might resemble real words or even coherent sentences.
One day, one of the circus trainers sees that a monkey has written out “To be, or not to be,” so the trainer gives the monkey a treat.
The other monkeys see this and start trying to imitate the successful monkey, hoping for their own treat.
As time passes, some monkeys start to consistently produce better and more coherent text strings, while others continue to produce gibberish.
Eventually, the monkeys can recognize and even emulate coherent patterns in text.
LLMs have a leg up on the monkeys because LLMs are first trained on billions of pieces of text. They can already see the patterns. They also understand the vectors and relationships between these pieces of text.
This means they can use those patterns and relationships to generate new text that resembles natural language.
GPT, which stands for Generative Pre-trained Transformer, is a language model that uses transformers to generate natural language text.
It was trained on a massive amount of text from the internet, which allowed it to learn the patterns and relationships between words and phrases in natural language.
The model works by taking in a prompt or a few words of text and using the transformers to predict what words should come next based on the patterns it has learned from its training data.
The model continues to generate text word by word, using the context of the previous words to inform the next ones.
GPT in action
One of the benefits of GPT is that it can generate natural language text that is highly coherent and contextually relevant.
This has many practical applications, such as generating product descriptions or answering customer service queries. It can also be used creatively, such as generating poetry or short stories.
However, it is only a language model. It’s trained on data, and that data can be out of date or incorrect.
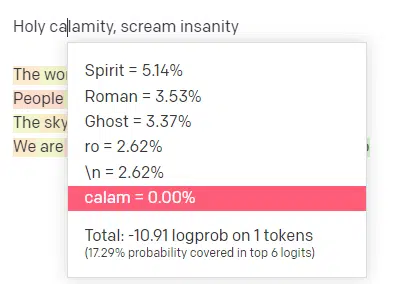
I submitted the response so we can see the likelihood of both of my input and the output lines. So let’s go through each part of what this tells us.
For the first word/token, I input “Holy.” We can see that the most expected next input is Spirit, Roman, and Ghost.
We can also see that the top six results cover only 17.29% of the probabilities of what comes next: which means that there are ~82% other possibilities we can’t see in this visualization.
Let’s briefly discuss the different inputs you can use in this and how they affect your output.
Temperature is how likely the model is to grab words other than those with the highest probability, top P is how it selects those words.
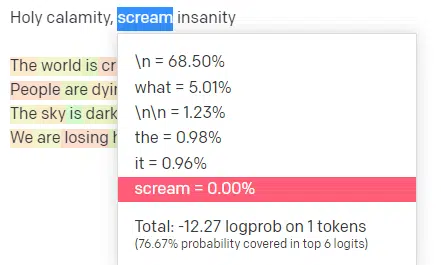
So for the input “Holy Calamity,” top P is how we select the cluster of next tokens [Ghost, Roman, Spirit], and temperature is how likely it is to go for the most likely token vs. more variety.
If the temperature is higher, it is more likely to choose a less likely token.
So a high temperature and a high top P will likely be wilder. It’s choosing from a wide variety (high top P) and is more likely to choose surprising tokens.
A selection of high temp, high P responses
While a high temp but lower top P will pick surprising options from a smaller sample of possibilities:
And lowering the temperature just chooses the most likely next tokens:
Playing with these probabilities can, in my opinion, give you a good insight into how these kinds of models work.
It is looking at a collection of probable next selections based on what is already completed
What does this mean actually?
Simply put, LLMs take in a collection of inputs, shake them up, and turn them into outputs.
I’ve heard people joke about whether that’s so different from people.
But it’s not like people – LLMs have no knowledge base. They aren’t extracting information about a thing. They’re guessing a sequence of words based on the last one.
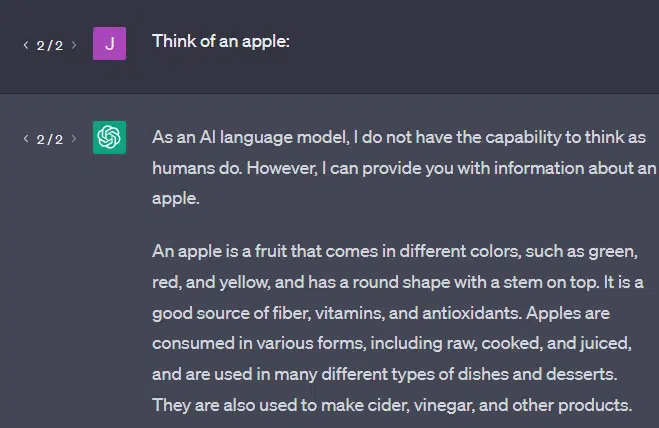
Another example: think of an apple. What comes to mind?
Maybe you can rotate one in your mind.
Perhaps you remember the smell of an apple orchard, the sweetness of a pink lady, etc.
Maybe you think of Steve Jobs.
Now let’s see what a prompt “think of an apple” returns.
You’ve probably heard the words “Stochastic Parrots” floating around by this point.
Stochastic Parrots is a term used to describe LLMs like GPT. A parrot is a bird that mimics what it hears.
So, LLMs are like parrots in that they take in information (words) and output something that resembles what they’ve heard. But they’re also stochastic, which means they use probability to guess what comes next.
LLMs are good at recognizing patterns and relationships between words, but they don’t have any deeper understanding of what they’re seeing. That’s why they’re so good at generating natural language text but not understanding it.
Good uses for an LLM
LLMs are good at more generalist tasks.
You can show it text, and without training, it can do a task with that text.
You can throw it some text and ask for sentiment analysis, ask it to transfer that text to structured markup, and even do some creative work, like writing outlines.
It’s OK at stuff like code. For many tasks, it can almost get you there.
But again, it’s based on probability and patterns. So there will be times when it picks up on patterns in your input that you don’t know are there.
This can be positive (seeing patterns that humans can’t), but it can also be negative (why did it respond like this?).
It also doesn’t have access to any sort of data sources. SEOs who use it to look up ranking keywords will have a bad time.
It can’t look up traffic for a keyword. It doesn’t have the information for keyword data beyond that words exist.
The exciting thing about ChatGPT is that it is an easily available language model you can use out of the box on various tasks. But it isn’t without caveats.
Good uses for other ML models
I hear people say they’re using LLMs for certain tasks, which other NLP algorithms and techniques can do better.
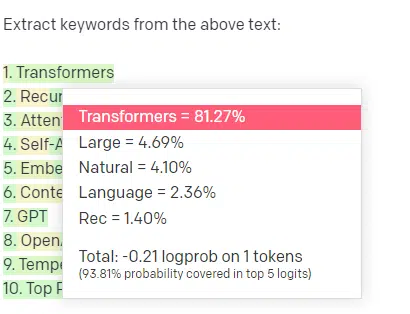
Let’s take an example, keyword extraction.
If I use TF-IDF, or another keyword technique, to extract keywords from a corpus, I know what calculations are going into that technique.
This means that the results will be standard, reproducible, and I know they will be related specifically to that corpus.
With LLMs like ChatGPT, if you are asking for keyword extraction, you aren’t necessarily getting the keywords extracted from the corpus. You’re getting what GPT thinks a response to corpus + extract keywords would be.
This is similar to tasks like clustering or sentiment analysis. You aren’t necessarily getting the fine-tuned result with the parameters you set. You’re getting what there is some probability of based on other similar tasks.
Again, LLMs have no knowledge base and no current information. They often cannot search the web, and they parse what they get from information as statistical tokens. The restrictions on how long an LLM’s memory lasts are because of these factors.
Another thing is that these models can’t think. I only use the word “think” a few times throughout this piece because it’s really difficult not to use it when talking about these processes.
The tendency is toward anthropomorphism, even when discussing fancy statistics.
But this means that if you entrust an LLM to any task needing “thought,” you are not trusting a thinking creature.
You’re trusting a statistical analysis of what hundreds of internet weirdos respond to similar tokens with.
If you would trust internet denizens with a task, then you can use an LLM. Otherwise…
Things that should never be ML models
A chatbot run through a GPT model (GPT-J) reportedly encouraged a man to kill himself. The combination of factors can cause real harm, including:
People anthropomorphizing these responses.
Believing them to be infallible.
Using them in places where humans need to be in the machine.
And more.
While you may think, “I’m an SEO. I don’t have a hand in systems that could kill someone!”
Think about YMYL pages and how Google promotes concepts like E-A-T.
Does Google do this because they want to annoy SEOs, or is it because they don’t want the culpability of that harm?
Even in systems with strong knowledge bases, harm can be done.
The above is a Google knowledge carousel for “flowers safe for cats and dogs.” Daffodils are on that list despite being toxic to cats.
Let’s say you are generating content for a veterinary website at scale using GPT. You plug in a bunch of keywords and ping the ChatGPT API.
You have a freelancer read all the results, and they are not a subject expert. They don’t pick up on a problem.
You publish the result, which encourages buying daffodils for cat owners.
You kill someone’s cat.
Not directly. Maybe they don’t even know it was that site particularly.
Maybe the other vet sites start doing the same thing and feeding off each other.
The top Google search result for “are daffodils toxic to cats” is a site saying they are not.
Other freelancers reading through other AI content – pages upon pages of AI content – actually fact-check. But the systems now have incorrect information.
When discussing this current AI boom, I mention the Therac-25 a lot. It is a famous case study of computer malfeasance.
Basically, it was a radiation therapy machine, the first to use only computer locking mechanisms. A glitch in the software meant people got tens of thousands of times the radiation dose they should have.
Something that always sticks out to me is that the company voluntarily recalled and inspected these models.
But they assumed that since the technology was advanced and software is “infallible,” the problem had to do with the machine’s mechanical parts.
Thus, they repaired the mechanisms but didn’t check the software – and the Therac-25 stayed on the market.
FAQs and misconceptions
Why does ChatGPT lie to me?
One thing I’ve seen from some of the greatest minds of our generation and also influencers on Twitter is a complaint that ChatGPT “lies” to them. This is due to a couple of misconceptions in tandem:
That ChatGPT has “wants.”
That it has a knowledge base
That the technologists behind the technology have some sort of agenda beyond “make money” or “make a cool thing.”
Biases are baked into every part of your day-to-day life. So are exceptions to these biases.
Most software developers currently are men: I am a software developer and a woman.
Training an AI based on this reality would lead to it always assuming software developers are men, which is not true.
A famous example is Amazon’s recruiting AI, trained on resumes from successful Amazon employees.
This led to it discarding resumes from majority black colleges, even though many of those employees could’ve been extremely successful.
To counter these biases, tools like ChatGPT use layers of fine-tuning. This is why you get the “As an AI language model, I cannot…” response.
Some workers in Kenya had to go through hundreds of prompts, looking for slurs, hate speech, and just downright terrible responses and prompts.
Then a fine-tuning layer was created.
Why can’t you make up insults about Joe Biden? Why can you make sexist jokes about men and not women?
It’s not due to liberal bias but because of thousands of layers of fine-tuning telling ChatGPT not to say the N-word.
Ideally, ChatGPT would be entirely neutral about the world, but they also need it to reflect the world.
It’s a similar problem to the one that Google has…
What is true, what makes people happy, and what makes a correct response to a prompt are often all very different things.
Why does ChatGPT come up with fake citations?
Another question I see come up frequently is about fake citations. Why are some of them fake and some real? Why are some websites real, but the pages fake?
Hopefully, by reading how the statistical models work, you can parse this out.
But in case you skipped the extremely long expectation, let’s make a shorter one here.
You’re an AI language model. You have been trained on a ton of the web.
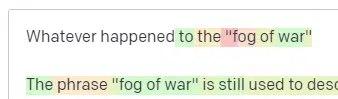
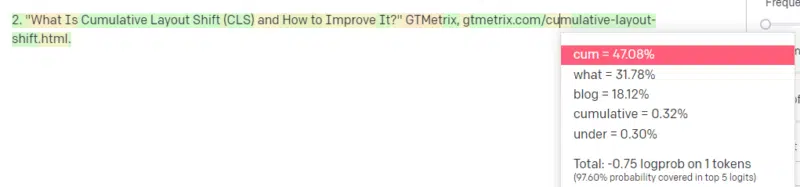
Someone tells you to write about a technological thing – let’s say Cumulative Layout Shift.
You don’t have a ton of examples of CLS papers, but you know what it is, and you know the general shape of an article about technologies. You know the pattern of what this kind of article looks like.
So you get started with your response and run into a kind of problem. In the way you understand technical writing, you know a URL should go next in your sentence.
Well, from other CLS articles, you know that Google and GTMetrix are often cited about CLS, so those are easy.
But you also know that CSS-tricks is often linked to in web articles: you know that usually CSS-tricks URLs look a certain way: so you can construct a CSS-tricks URL like this:
The trick is: this is how all the URLs are constructed, not just the fake ones:
This GTMetrix article does exist: but it exists because it was a likely string of values to come at the end of this sentence.
GPT and similar models cannot distinguish between a real citation and a fake one.
The only way to do that modeling is to use other sources (knowledge bases, Python, etc.) to parse that difference and check the results.
What is a ‘Stochastic Parrot’?
I know I went over this already, but it bears repeating. Stochastic Parrots are a way of describing what happens when large language models seem generalist in nature.
To the LLM, nonsense and reality is the same thing. They see the world the same way an economist does, as a bunch of statistics and numbers describing reality.
You know the quote, “There are three kinds of lies: lies, damned lies, and statistics.”
LLMs are a big bunch of statistics.
LLMs seem coherent, but that is because we fundamentally see things that appear human as human.
Similarly, the chatbot model obfuscates much of the prompting and information you need for GPT responses to be fully coherent.
I’m a developer: trying to use LLMs to debug my code has extremely variable results. If it is an issue similar to one people have often had online, then LLMs can pick up on and fix that result.
If it is an issue that it hasn’t come across before, or is a small part of the corpus, then it will not fix anything.
Why is GPT better than a search engine?
I worded this in a spicy way. I don’t think GPT is better than a search engine. It worries me that people have replaced searching with ChatGPT.
One underrecognized part of ChatGPT is how much it exists to follow instructions. You can ask it to basically do anything.
But remember, it’s all based on the statistical next word in a sentence, not the truth.
So if you ask it a question that has no good answer but ask it in a way that it is obligated to answer, you will get an answer: a poor one.
Having a response designed for you and around you is more comforting, but the world is a mass of experiences.
All of the inputs into an LLM are treated the same: but some people have experience, and their response will be better than a melange of other people’s responses.
One expert is worth more than a thousand think pieces.
Is this the dawning of AI? Is Skynet here?
Koko the Gorilla was an ape who was taught sign language. Researchers in linguistic studies did tons of research showing that apes could be taught language.
Herbert Terrace then discovered the apes weren’t putting together sentences or words but simply aping their human handlers.
People saw her as a person: a therapist they trusted and cared for. They asked researchers to be alone with her.
Language does something very specific to people’s brains. People hear something communicate and expect thought behind it.
LLMs are impressive but in a way that shows a breadth of human achievement.
LLMs don’t have wills. They can’t escape. They can’t try and take over the world.
They’re a mirror: a reflection of people and the user specifically.
The only thought there is a statistical representation of the collective unconscious.
Did GPT learn a whole language by itself?
Sundar Pichai, CEO of Google, went on 60 Minutes and claimed that Google’s language model learned Bengali.
The model was trained on those texts. It is incorrect that it “spoke a foreign language it was never trained to know.”
There are times when AI does unexpected things, but that in itself is expected.
When you’re looking at patterns and statistics on a grand scale, there will necessarily be times when those patterns reveal something surprising.
What this truly reveals is that many of the C-suite and marketing folks who are peddling AI and ML don’t actually understand how the systems work.
I’ve heard some people who are very smart talk about emergent properties, AGI, and other futuristic things.
I may just be a simple country ML ops engineer, but it shows how much hype, promises, science fiction, and reality get thrown together when talking about these systems.
Elizabeth Holmes, the infamous founder of Theranos, was crucified for making promises that could not be kept.
But the cycle of making impossible promises is part of startup culture and making money. The difference between Theranos and AI hype is that Theranos couldn’t fake it for long.
Is GPT a black box? What happens to my data in GPT?
GPT is, as a model, not a black box. You can see the source code for GPT-J and GPT-Neo.
OpenAI’s GPT is, however, a black box. OpenAI has not and will likely try not to release its model, as Google doesn’t release the algorithm.
But it isn’t because the algorithm is too dangerous. If that were true, they wouldn’t sell API subscriptions to any silly guy with a computer. It’s because of the value of that proprietary codebase.
When you use OpenAI’s tools, you are training and feeding their API on your inputs. This means everything you put into the OpenAI feeds it.
This means people who have used OpenAI’s GPT model on patient data to help write notes and other things have violated HIPAA. That information is now in the model, and it will be extremely difficult to extract it.
Because so many people have difficulties understanding this, it’s very likely the model contains tons of private data, just waiting for the right prompt to release it.
There is no easy way to avoid this. How can you have something recognize or understand hatred, biases, and violence without having it as a part of your training set?
How do you avoid biases and understand implicit and explicit biases when you’re a machine agent statistically selecting the next token in a sentence?
TL;DR
Hype and misinformation are currently major elements of the AI boom. That doesn’t mean there aren’t legitimate uses: this technology is amazing and useful.
But how the technology is marketed and how people use it can foster misinformation, plagiarism, and even cause direct harm.
Do not use LLMs when life is on the line. Do not use LLMs when a different algorithm would do better. Do not get tricked by the hype.
Understanding what LLMs are – and are not – is necessary
Although no one likes a know-it-all, they dominate the Internet.
The Internet began as a vast repository of information. It quickly became a breeding ground for self-proclaimed experts seeking what most people desire: recognition and money.
Today, anyone with an Internet connection and some typing skills can position themselves, regardless of their education or experience, as a subject matter expert (SME). From relationship advice, career coaching, and health and nutrition tips to citizen journalists practicing pseudo-journalism, the Internet is awash with individuals—Internet talking heads—sharing their “insights,” which are, in large part, essentially educated guesses without the education or experience.
The Internet has become a 24/7/365 sitcom where armchair experts think they’re the star.
Not long ago, years, sometimes decades, of dedicated work and acquiring education in one’s field was once required to be recognized as an expert. The knowledge and opinions of doctors, scientists, historians, et al. were respected due to their education and experience. Today, a social media account and a knack for hyperbole are all it takes to present oneself as an “expert” to achieve Internet fame that can be monetized.
On the Internet, nearly every piece of content is self-serving in some way.
The line between actual expertise and self-professed knowledge has become blurry as an out-of-focus selfie. Inadvertently, social media platforms have created an informal degree program where likes and shares are equivalent to degrees. After reading selective articles, they’ve found via and watching some TikTok videos, a person can post a video claiming they’re an herbal medicine expert. Their new “knowledge,” which their followers will absorb, claims that Panda dung tea—one of the most expensive teas in the world and isn’t what its name implies—cures everything from hypertension to existential crisis. Meanwhile, registered dietitians are shaking their heads, wondering how to compete against all the misinformation their clients are exposed to.
More disturbing are individuals obsessed with evangelizing their beliefs or conspiracy theories. These people write in-depth blog posts, such as Elvis Is Alive and the Moon Landings Were Staged, with links to obscure YouTube videos, websites, social media accounts, and blogs. Regardless of your beliefs, someone or a group on the Internet shares them, thus confirming your beliefs.
Misinformation is the Internet’s currency used to get likes, shares, and engagement; thus, it often spreads like a cosmic joke. Consider the prevalence of clickbait headlines:
You Won’t Believe What Taylor Swift Says About Climate Change!
This Bedtime Drink Melts Belly Fat While You Sleep!
In One Week, I Turned $10 Into $1 Million!
Titles that make outrageous claims are how the content creator gets reads and views, which generates revenue via affiliate marketing, product placement, and pay-per-click (PPC) ads. Clickbait headlines are how you end up watching a TikTok video by a purported nutrition expert adamantly asserting you can lose belly fat while you sleep by drinking, for 14 consecutive days, a concoction of raw eggs, cinnamon, and apple cider vinegar 15 minutes before going to bed.
Our constant search for answers that’ll explain our convoluted world and our desire for shortcuts to success is how Internet talking heads achieve influencer status. Because we tend to seek low-hanging fruits, we listen to those with little experience or knowledge of the topics they discuss yet are astute enough to know what most people want to hear.
There’s a trend, more disturbing than spreading misinformation, that needs to be called out: individuals who’ve never achieved significant wealth or traded stocks giving how-to-make-easy-money advice, the appeal of which is undeniable. Several people I know have lost substantial money by following the “advice” of Internet talking heads.
Anyone on social media claiming to have a foolproof money-making strategy is lying. They wouldn’t be peddling their money-making strategy if they could make easy money.
Successful people tend to be secretive.
Social media companies design their respective algorithms to serve their advertisers—their source of revenue—interest; hence, content from Internet talking heads appears most prominent in your feeds. When a video of a self-professed expert goes viral, likely because it pressed an emotional button, the more people see it, the more engagement it receives, such as likes, shares and comments, creating a cycle akin to a tornado.
Imagine scrolling through your TikTok feed and stumbling upon a “scientist” who claims they can predict the weather using only aluminum foil, copper wire, sea salt and baking soda. You chuckle, but you notice his video got over 7,000 likes, has been shared over 600 times and received over 400 comments. You think to yourself, “Maybe this guy is onto something.” What started as a quest to achieve Internet fame evolved into an Internet-wide belief that weather forecasting can be as easy as DIY crafts.
Since anyone can call themselves “an expert,” you must cultivate critical thinking skills to distinguish genuine expertise from self-professed experts’ self-promoting nonsense. While the absurdity of the Internet can be entertaining, misinformation has serious consequences. The next time you read a headline that sounds too good to be true, it’s probably an Internet talking head making an educated guess; without the education seeking Internet fame, they can monetize.
TORONTO – A new survey says a majority of software engineers and developers feel tight project deadlines can put safety at risk.
Seventy-five per cent of the 1,000 global workers who responded to the survey released Tuesday say pressure to deliver projects on time and on budget could be compromising critical aspects like safety.
The concern is even higher among engineers and developers in North America, with 77 per cent of those surveyed on the continent reporting the urgency of projects could be straining safety.
The study was conducted between July and September by research agency Coleman Parkes and commissioned by BlackBerry Ltd.’s QNX division, which builds connected-car technology.
The results reflect a timeless tug of war engineers and developers grapple with as they balance the need to meet project deadlines with regulations and safety checks that can slow down the process.
Finding that balance is an issue that developers of even the simplest appliances face because of advancements in technology, said John Wall, a senior vice-president at BlackBerry and head of QNX.
“The software is getting more complicated and there is more software whether it’s in a vehicle, robotics, a toaster, you name it… so being able to patch vulnerabilities, to prevent bad actors from doing malicious acts is becoming more and more important,” he said.
The medical, industrial and automotive industries have standardized safety measures and anything they produce undergoes rigorous testing, but that work doesn’t happen overnight. It has to be carried out from the start and then at every step of the development process.
“What makes safety and security difficult is it’s an ongoing thing,” Wall said. “It’s not something where you’ve done it, and you are finished.”
The Waterloo, Ont.-based business found 90 per cent of its survey respondents reported that organizations are prioritizing safety.
However, when asked about why safety may not be a priority for their organization, 46 per cent of those surveyed answered cost pressures and 35 per cent said a lack of resources.
That doesn’t surprise Wall. Delays have become rampant in the development of tech, and in some cases, stand to push back the launch of vehicle lines by two years, he said.
“We have to make sure that people don’t compromise on safety and security to be able to get products out quicker,” he said.
“What we don’t want to see is people cutting corners and creating unsafe situations.”
The survey also took a peek at security breaches, which have hit major companies like London Drugs, Indigo Books & Music, Giant Tiger and Ticketmaster in recent years.
About 40 per cent of the survey’s respondents said they have encountered a security breach in their employer’s operating system. Those breaches resulted in major impacts for 27 per cent of respondents, moderate impacts for 42 per cent and minor impacts for 27 per cent.
“There are vulnerabilities all the time and this is what makes the job very difficult because when you ship the software, presumably the software has no security vulnerabilities, but things get discovered after the fact,” Wall said.
Security issues, he added, have really come to the forefront of the problems developers face, so “really without security, you have no safety.”
This report by The Canadian Press was first published Oct. 8, 2024.
As online shoppers hunt for bargains offered by Amazon during its annual fall sale this week, cybersecurity researchers are warning Canadians to beware of an influx of scammers posing as the tech giant.
In the 30 days leading up to Amazon’s Prime Big Deal Days, taking place Tuesday and Wednesday, there were more than 1,000 newly registered Amazon-related web domains, according to Check Point Software Technologies, a company that offers cybersecurity solutions.
The company said it deemed 88 per cent of those domains malicious or suspicious, suggesting they could have been set up by scammers to prey on vulnerable consumers. One in every 54 newly created Amazon-related domain included the phrase “Amazon Prime.”
“They’re almost indiscernible from the real Amazon domain,” said Robert Falzon, head of engineering at Check Point in Canada.
“With all these domains registered that look so similar, it’s tricking a lot of people. And that’s the whole intent here.”
Falzon said Check Point Research sees an uptick in attempted scams around big online shopping days throughout the year, including Prime Days.
Scams often come in the form of phishing emails, which are deceptive messages that appear to be from a reputable source in attempt to steal sensitive information.
In this case, he said scammers posing as Amazon commonly offer “outrageous” deals that appear to be associated with Prime Days, in order to trick recipients into clicking on a malicious link.
The cybersecurity firm said it has identified and blocked 100 unique Amazon Prime-themed scam emails targeting organizations and consumers over the past two weeks.
Scammers also target Prime members with unsolicited calls, claiming urgent account issues and requesting payment information.
“It’s like Christmas for them,” said Falzon.
“People expect there to be significant savings on Prime Day, so they’re not shocked that they see something of significant value. Usually, the old adage applies: If it seems too good to be true, it probably is.”
Amazon’s website lists a number of red flags that it recommends customers watch for to identify a potential impersonation scam.
Those include false urgency, requests for personal information, or indications that the sender prefers to complete the purchase outside of the Amazon website or mobile app.
Scammers may also request that customers exclusively pay with gift cards, a claim code or PIN. Any notifications about an order or delivery for an unexpected item should also raise alarm bells, the company says.
“During busy shopping moments, we tend to see a rise in impersonation scams reported by customers,” said Amazon spokeswoman Octavia Roufogalis in a statement.
“We will continue to invest in protecting consumers and educating the public on scam avoidance. We encourage consumers to report suspected scams to us so that we can protect their accounts and refer bad actors to law enforcement to help keep consumers safe.”
Falzon added that these scams are more successful than people might think.
As of June 30, the Canadian Anti-Fraud Centre said there had been $284 million lost to fraud so far this year, affecting 15,941 victims.
But Falzon said many incidents go unreported, as some Canadians who are targeted do not know how or where to flag a scam, or may choose not to out of embarrassment.
Check Point recommends Amazon customers take precautions while shopping on Prime Days, including by checking URLs carefully, creating strong passwords on their accounts, and avoiding personal information being shared such as their birthday or social security number.
The cybersecurity company said consumers should also look for “https” at the beginning of a website URL, which indicates a secure connection, and use credit cards rather than debit cards for online shopping, which offer better protection and less liability if stolen.
This report by The Canadian Press was first published Oct. 8, 2024.